Relevanz des Themas
Als „Big Data“ werden Massendaten bezeichnet, die in Form sehr großer Datensätze in hoher Frequenz und mit hohem Anteil personalisierter Informationen entstehen. Beispiele hierfür sind Daten, die von intelligenten Sensoren in Haushalten oder in den virtuellen sozialen Medien gesammelt werden. Etablierte ökonometrische Methoden reichen zur Bewältigung kleinerer Datenmengen aus, doch Big Data verlangen nach dem Einsatz maschineller Lernverfahren und neuer analytischer Ansätze, um diese ergiebigen Daten in den Wirtschaftswissenschaften optimal nutzen zu können.
Wichtige Resultate
Pro
Big Data zeichnen sich durch Komplexität, großes Volumen, rasche Entstehungsgeschwindigkeit, breite Varianz und die Möglichkeit aus, umfassende Verknüpfungen zu anderen Datensätzen herzustellen.
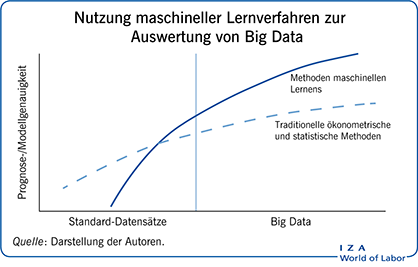
Leistungsstarke neue Analysetechniken auf Basis von Maschinenlernen werden im ökonometrischen Repertoire immer wichtiger.
Big Data ermöglichen eine genauere Prognose von wirtschaftlichen Ereignissen und lassen präzisere Kausalschlüsse zu.
Maschinelle Lernverfahren erleichtern die Konzeption einfacher Modelle zur Auswertung komplexer Datensätze.
Die Kombination von Big Data und maschinellen Lernmethoden gestattet die Modellierung komplexer Zusammenhänge weit über die Datenstichprobe hinaus.
Contra
Die Nutzung von Big Data kann Fragen hinsichtlich des Schutzes der Privatsphäre aufwerfen.
Maschinelle Lernverfahren sind rechenintensiv, bieten nicht immer eindeutige Lösungen und erfordern möglicherweise eine hohe Feinabstimmung.
Die Erhebung und Speicherung von Big Data ist kostenintensiv; ihre Analyse setzt Investitionen in Technologie und menschliche Analysefähigkeiten voraus.
Je nach Art ihrer Erhebung bringen Big Data das Risiko von Selektionsverzerrungen mit sich.
Der Zugang zu Big Data setzt oft Vereinbarungen mit den datenproduzierenden Institutionen voraus und kann die Freiheit der Forschung durch eingeschränkte Datennutzung begrenzen.