Elevator pitch
Information from longitudinal surveys transforms snapshots of a given moment into something with a time dimension. It illuminates patterns of events within an individual’s life and records mobility and immobility between older and younger generations. It can track the different pathways of men and women and people of diverse socio-economic background through the life course. It can join up data on aspects of a person’s life, health, education, family, and employment and show how these domains affect one another. It is ideal for bridging the different silos of policies that affect people’s lives.
Key findings
Pros
Longitudinal surveys form a record of continuities and transitions of a life as they happen, information not reliably gained through recollection or cross-section surveys.
Such surveys can reveal how domains of life intertwine over time in the same person.
Information from an individual’s past helps unpack present observations and future expectations for that person.
Multiple applications and an ability to link to administrative data make longitudinal surveys cost-effective.
Analyses of such survey data may detect causation within correlation.
Cons
Longitudinal survey data are expensive to collect and challenging to analyze.
Data must be collected over a long timeframe to show relevant, long-term results.
Having usable longitudinal survey data requires that informants not drop out of the survey, which limits how much information they can be asked to provide.
Data confidentiality has to be safeguarded, putting hurdles across easy research access.
Caution is needed in inferring causality from observational data, where changes may not be independently generated.
Author's main message
The rich data from longitudinal surveys can illuminate patterns and drivers of change within a lifetime and across generations. Data collected on the same individuals over time can relate outcomes at one time to information on the past and record interdependence among domains, such as health, wealth, and education. The dynamic perspective on linked developments in work and family roles can guide policy by revealing, for example, converging patterns in men’s and women’s lives and trends in social inequalities in life chances. Longitudinal surveys can inform policy in many arenas, making it important to find ways to finance and sustain them.
Motivation
Economists have long been interested in the life-cycle but have relied either on aggregate data or on repeat cross-sections of micro-data. Longitudinal surveys enrich the evidence by tracking the same person across points in time, marking transitions in the labor market or other life domains. Behind the snapshot, the longitudinal dimension reveals duration, growth or decline, changes in more than one direction, and patterns of sequences. Repeated observations enable analysts to account for the effects of unobserved but fixed characteristics on outcomes. Longitudinal data can tell how long a particular state observed in the snapshot has been going on and what preceded it. Is its value going up, down, or fluctuating? Does it show mobility, stability, or instability? Are there regular or recognizable patterns over time? Do individuals maintain a constant position, or is there movement in and out of particular states (churning), such as unemployment or low pay?
Notionally, the entity whose history is followed in longitudinal data might be a firm, a household, or a person, but this paper concentrates on the tracking of individual people. Longitudinal data can, for example, help identify what are the life chances of a poor child and how and where life chances differ if the child is a girl. Comparing data on the same individual over time and across domains can reveal when and whether people become parents, how they combine work and family life, and how they transmit advantages to their children. When people born in different years are followed over time, their different historical contexts can be compared. Their stories have compelling interest to many academic disciplines.
Information on the past helps anticipate the future. The contemporary correlation of a pair of variables might reflect a causal relationship in either direction or none, but their ordering through time helps establish causality. However “before” and “after” observations may not be sufficient for modeling complex reciprocal relationships where variables feed back on one another. Behavior may anticipate the future, such as choosing a family-friendly occupation if expecting to have children later.
Discussion of pros and cons
A simplified model of men’s and women’s earnings profiles
A stylized example can show why longitudinal data are so important. Consider an issue of considerable concern today: the diverging earnings profiles of men and women as they move into mid-life.
Figure 1 is a simplified picture of lifetime earnings for men and women of mid-level skill living through a hypothetical lifetime but ignoring historical change (living in a “time-warp”). The model uses a mix of longitudinal, current, and retrospective data to construct earnings profiles as though conditions in the UK in the 1990s held forever. By holding characteristics like education constant, the model ignores differences between cohorts (people born at different dates) (see Examples of longitudinal cohort and panel studies) that affect contemporary comparison across ages in real data. The model allows wages to be affected by previous work history as well as gender [2].
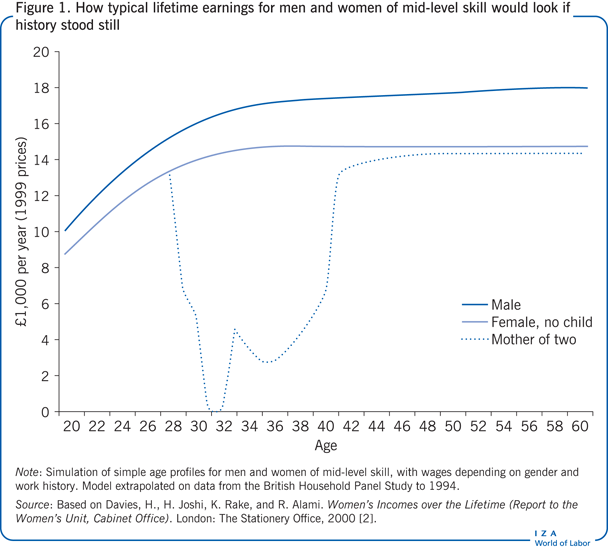
The divergence in lifetime incomes between men and women occurs for two main, interrelated reasons—unequal pay for men and women with identical education, experience, and hours of work, and the earnings consequences of combining employment and motherhood (the mother is assumed here to have two children). The mother’s earnings are reduced below those in the childless scenario because of absences from the labor market (the steep earnings dips at ages 31 and 35), part-time employment, and loss of earning power when she returns to full-time work. The size of each effect is sensitive to a host of assumptions. For example, the earnings forgone by a mother depend on her education and her age at motherhood, but such variants are not considered in the figure. The example illustrates the need for longitudinal data to explore the relationships that were simply assumed in the time-warp exercise. Some processes behind the stylized example are investigated in analyses of British cohort studies, such as the widening hourly pay gap between men and women as they enter mid-life and the impact of motherhood on employment trajectories. These are discussed below, along with some other applications of longitudinal data.
Gender patterns of pay, employment, and family arrangements
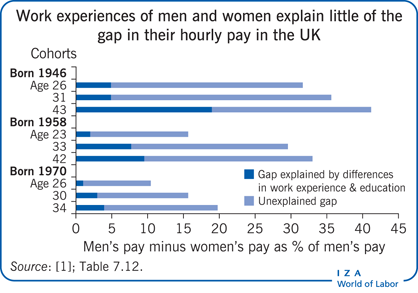
The Illustration takes data from the British cohort studies of people born in 1946, 1958, and 1970. Evidence from earlier life is used to investigate how much differences in employment experience, education, or ability assessed in childhood account for divergence in pay for men and women as they advance into mid-life [1].
Pay gaps between men and women in the three cohorts are recorded here at three points up to mid-career. The gaps in women’s pay narrow across cohorts for those employed in their twenties, from 32% of men’s pay in the 1946 cohort at age 26 in 1972, to 10% in 1996 when members of the 1970 cohort were 26 (equal pay legislation came into force in 1975). As each cohort grew older, women’s pay fell further behind men’s. This much would have been apparent in standard labor statistics. The longitudinal evidence helps assess whether this was simply a result of women interrupting their employment over these years for childbearing, missing out on the rewards of continuous employment that was more common among men. The analysis also controls for differences in educational attainment between men and women and in their cognitive test scores as children. While data on educational qualifications and gaps in employment can be collected from adults, perhaps unreliably, evidence of early cognitive ability cannot be established retrospectively.
The analysis, which allows for differences in education, experience, and skills (human capital) between men and women, finds a premium in the labor market for being male (the part of the gender pay gap that is unexplained by difference in human capital). This male pay premium did not entirely disappear with the introduction of equal opportunity laws in the mid-1970s; there was still some sign of it around the turn of the millennium. As in Figure 1, the gender premium tends to widen at ages when women are more likely to have responsibility for children. Further investigation (not shown) reveals that the pay gap is particularly large for women who work part-time, many of whom have children and previous employment interruptions. However, the wage penalties of motherhood are not uniform. They are mitigated for the increasing number of women who combine careers and child-rearing by using leave and flexible employment options. Institutional variations in labor market and social policies across countries and time generate a wide spread in the international experience of a “family gap” in women’s wages.
In another study, the British cohorts were used to classify sequences of employment and family building into groups with similar patterns [3]. Figure 2 shows the percentages of the 1946 and 1970 cohorts whose histories, each to age 42, are best described by the patterns identified. The patterns for the 1958 cohort, intermediate between those for the 1946 and 1970 cohorts, have been left out to show a clearer picture of change.
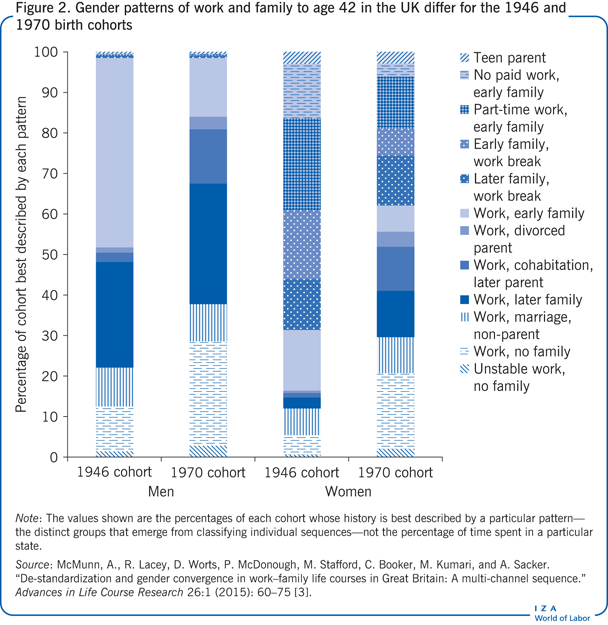
As in the analysis of wages in the Illustration, the patterns of employment and family histories to mid-life show some convergence between men and women, but not the complete elimination of female economic disadvantage. Figure 2 shows that year-by-year histories of employment and family arrangements became increasingly diversified between the 1946 and 1970 cohorts. Patterns of labor force participation to mid-life have shifted from the traditional gender division of labor. Comparing data across different cohorts helps in understanding and monitoring demographic trends, in this case toward delayed childbearing and away from marital stability. It is also useful to inform expectations about women’s income prospects in old age or after divorce.
Among cohort members who had children, patterns distinguish between those who had them early and those who had them late, with age 30 being the dividing line. Both men and women born in 1970 who had children before age 42 had them later than men and women born in 1946. Men’s employment histories are dominated by full-time employment, as might be safe to assume even from a cross-section of data and as was assumed in the ultra-stylized lifetime profile in Figure 1. Very few men had employment histories characterized by part-time employment or work breaks, while two-thirds of women born in 1946 and one-third of women born in 1970 did. A larger share of women in the 1970 cohort had predominantly full-time jobs, because more of them had no children and more of them combined motherhood with minimally interrupted employment. The convergence of employment patterns between men and women and the postponement of childbearing were both associated with higher education. The advance toward gender equality was slower for less-educated women. Part-time employment, with its attendant low pay, was associated with earlier motherhood.
How parents’ circumstances can affect children
Longitudinal data have also been analyzed to assess the impact on children of parents’ employment and relationships with their partners. One question concerns the effects that a mother’s employment may have on very young children. A study that looked at five child cohort studies (in Australia, Canada, Denmark, the UK, and the US) from around 2000 found little if any impact of a mother’s employment on children’s cognitive and behavioral development [4]. Where mothers with children under six months old worked full-time, there were a few statistically significant adverse findings, but these small estimates were dwarfed into substantive insignificance by the strong associations of child well-being with parental income and educational resources.
Many studies have used longitudinal data to explore the impact on children’s academic achievement of disruptions in their parents’ partnership. Among others, two used data on siblings to test assumptions of causality, one using the British Household Panel Study [5], and another using Swedish register data [6]. Both conclude that the apparent disadvantage of the children whose parents separated was attributable to associated factors rather than the breakup itself.
Parental resources are strongly correlated with continuities in economic and social position across generations, as would be expected if a child’s human capital is correlated with that of their parents. Longitudinal evidence helps to monitor and explain patterns of intergenerational mobility. It can quantify the strength of correlations between parental resources and outcomes for offspring in childhood and adulthood.
While it is possible to analyze intergenerational mobility using retrospective data, particularly when variables are broad summaries of occupation and education, information collected at a comparable time in the life-cycle of both generations offers possibilities for more accurate and nuanced analysis. Not only can longitudinal data provide more reliable information on occupation and income and more detail on schooling, training, and higher education, but such data may also include assessments of cognitive and non-cognitive skills. The importance of non-cognitive skills as components of human capital is increasingly recognized, notably based on US evidence from the National Longitudinal Survey of Youth cohort, which starts in adolescence [7].
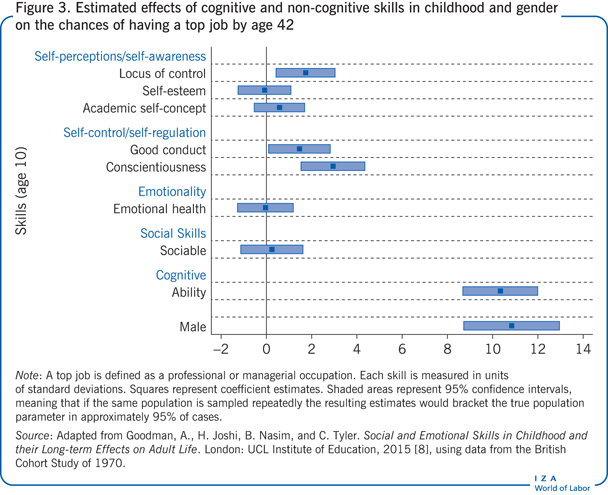
The mature British birth cohort studies have a wide selection of evidence on non-cognitive skills, including psychological strengths and weaknesses in childhood. An exercise relating a battery of non-cognitive skills to outcomes at age 42 for the 1970 cohort found that factors such as self-regulation, self-esteem, sociability, and emotional health, taken together with cognitive ability, had varying degrees of correlation with outcomes in educational attainment, employment, health, well-being, and family formation [8]. Non-cognitive skills seldom trumped cognitive ability, but they did make a contribution to the prediction of progress. While there were surprisingly few differences between men and women in the estimated effect of each skill, the estimates did suggest a distinct advantage to being male, which is in line with the finding of a male premium in wages shown in the Illustration. For example, in the analysis of the chances of getting a professional or managerial job as an adult, the estimated advantage for being male is about as big as that of having cognitive ability one standard unit higher (Figure 3). Non-cognitive skills with a significant contribution to this measure of occupational success (those relating to self-control/self-regulation and locus of control), do not, even jointly, approach the contribution of cognitive ability or the premium for being male. Non-cognitive skills were, however, more important in predicting other adult outcomes, particularly mental well-being.
Studies of intergenerational continuities in income level and education have also used longitudinal data. One found evidence for a stronger association with parental education in the British cohort of 1970 than in Sweden (register data) [9]. A much-cited analysis of the incomes of fathers and sons found a reduction in intergenerational mobility from the 1958 to the 1970 cohort in Britain [10]. The focus has been on men because of the difficulty of observing a woman’s permanent economic ranking in mid-life when she may be “off course” because of breaks for raising a family and may experience occupational downgrading on her return to the labor market. In a study of the British cohorts, sociologists describing trends in mobility by social class, rather than income, have recently attempted to include the social mobility of women [11]. This analysis broadly confirms that social class and income mobility are distinct, with little trend toward immobility in occupational class. There is also little gender difference in class mobility, with the exception of increasing, rather than decreasing, fluidity, possibly downward, for the most recent female cohorts.
Multidimensionality and interdisciplinary research
The discussion so far has focused on long-term surveys of cohorts, particularly those in the UK, as applied to a few examples of labor studies. However, longitudinal studies can illuminate many other economic topics, as well as other domains of human life, including information of primary interest to medicine, psychology, geography, demography, sociology, and education, as well as indicators of well-being of interest from many perspectives. This reach across disciplines, as well as across time, enriches the data set, taking individuals in the round rather than as actors in one particular field of study or as clients of one particular government agency. Epidemiologists benefit from information on family background, employment, and wealth as they trace health inequalities over the life course. Economists use biomarkers or controls for variables devised by psychologists, such as the non-cognitive skills appearing in Figure 3. Events in education, location, employment, and living arrangements are intertwined. The variety of purposes to which the data can be applied make generalist data sets more cost-effective than specialist studies and justify conducting them on a larger scale than could be afforded for a single-focus, limited-user enquiry. Not only is there scope for interdisciplinary collaboration in cross-domain research and policy advice, there is also scope for international collaboration and comparison, especially now that cohort studies are proliferating.
Linked administrative data
Linked administrative data registers covering entire populations have proven a valuable alternative to longitudinal survey data, especially in Scandinavian countries. An example from Sweden shows the use of administrative data in assessing the effect of family structure on the transmission of intergenerational advantage [6]. Another illustration uses Norwegian registry data to explore the long-term consequences of the age of starting school. Linking cohort or panel studies to administrative data can enhance the usefulness of both sources. Age at starting school was studied in England by linking local variation in school administration to the 1958 birth cohort data to establish more robust estimates [12]. More recently, it has been possible to exploit the National Pupil Database of all children in state schools in England, a valuable resource in itself as well as when matched with samples in the Millennium Cohort Study or Next Steps cohorts. Another promising development in US studies has been the linking of longitudinal tax return and social security data to ecological data from the census. Such data linkage has revealed the gains in adulthood of moving from a high-poverty to a low-poverty neighborhood in childhood [13].
Limitations and gaps
Longitudinal data, though a valuable resource, are not without drawbacks. Creating and maintaining long-term surveys of cohorts is expensive, and often they are not followed up. Two recent attempts to establish new large and complex national cohorts, the National Children’s Study in the US and the Life Study survey in the UK, have been abandoned. A shared problem was the unanticipated difficulty of recruiting participants in pregnancy (before the child had even been born), and plans to collect clinical data appear to have been over-ambitious.
Because it takes time to process the data once collected, the infrequent results take time to emerge. The investment in data collection does not produce a resource for the short term, yet most public funding is not geared to funding for the long term. Even existing studies are vulnerable in a lean funding climate.
And long-term surveys burden not only the public purse, but also respondents, who are inconvenienced by their participation with little or no remuneration. So even if funding allows for very long interviews, concerns about respondent burden pose a constraint. Respondents may find some questions intrusive and uncomfortable to answer, and they need to be assured that their response will remain confidential. Loss of cooperation is one source of survey dropout—the scourge of the longitudinal study. Surveys also lose respondents who move. Tracking movers is not impossible, but it is a cost that one-off data collections do not face. Even when participants who move are located, their geographic dispersion increases the cost of fieldwork.
Dropout is not the only reason a survey may become unrepresentative of the population over time. A panel or cohort study can become unrepresentative of its host population unless it recruits newcomers to that population, such as immigrants. Doing so is not without problems. There may not be a sampling frame to ensure the representativeness of sampled incomers. New recruits’ past histories will be incomplete. How much this matters depends on how much migration there is and how much those arriving and leaving differ from the original population. Another drawback is that the value of complete life histories becomes of historic rather than current interest as participants reach a very old age. This is less of a problem with panel studies, which start off with their subjects at a range of ages, than studies of a single cohort that start at birth or in youth.
For all their holistic attractions, multi-purpose surveys are limited in the amount of detail that can be collected on any one topic. Although multipurpose data are cost-effective, in that they can meet the needs of many users, they entail costs beyond those of their collection. Their complexity creates challenges for data management, archiving, and analysis. There may be a shortage of analysts with the requisite skills to exploit the methods that are being developed to handle longitudinal micro-data. The scarcity of analytic skills can limit the amount of use, which in turn limits the support for further investment in such data. In some cases, access is also inhibited by restrictions on who may use the data or by the protections surrounding confidentiality.
Summary and policy advice
This paper has discussed the utility of data collected prospectively on the same individuals over time in a number of domains. Unlike cross-sectional surveys, longitudinal surveys can provide information on duration, persistence, and sequences. They can relate outcomes at one point in time to information from the past, within or across domains and sometimes across generations. Longitudinal survey data can trace the consequences for the later course of life of accidents of birth and many aspects of the environment. The illustrations presented here reveal the incomplete long-term transition toward gender equality in the UK, as well as the persistent influences of family of origin.
Longitudinal data can also shed light on human capital accumulation and returns, as well as provision for old age. An individual’s progress through education and the labor market can be followed through multipurpose cohorts and panel studies in the context of at least some of the following domains: household membership, health, wealth, location, and attitudes. Linking data from multi-purpose cohorts and panel studies to administrative data can augment the usefulness of each data set for research. However, while the development of hybrid survey and record-linked data faces challenges on the data privacy and security front, it holds out the promise of reducing burdens on informants and improving the quality of official records.
The disadvantages of longitudinal surveys include the cost of collection, the long wait to observe long-term outcomes, incomplete follow-up, obstacles to access posed by the need to protect confidentiality, and the inherent limitation of inferring causality in observational data. These disadvantages and some recent failed attempts to sustain new studies should not, however, undermine the case for keeping existing cohorts going or for aspiring to start other, perhaps less ambitious, studies in the future.
A long-term infrastructure coordinating the capacity of longitudinal surveys to maintain contact with informants, collect, curate, and analyze data across domains, and nurture the careers of the specialist staff could overcome the disadvantages and reap many benefits for policy and research. It would involve multiple sources of funding and dissemination of results to many audiences, including a range of government agencies. The Cohort & Longitudinal Studies Enhancement Resources (CLOSER), which works with eight longitudinal studies in the UK to maximize the use, value, and impact of longitudinal studies, aims to provide such infrastructure for UK studies. It could be an example for other countries to follow.
Acknowledgments
The author thanks two anonymous referees and the IZA World of Labor editors for many helpful suggestions on earlier drafts. Thanks are also due to Alex Bryson and Alison Park for comments on previous drafts, to Jenny Neuburger for the data used in the Illustration, to the late Hugh Davies for his work behind Figure 1, to Anne McMunn and her co-authors for permission to derive Figure 2 from their work, and to Bilal Nasim for adapting our joint results to generate Figure 3. Previous work of the author and co-authors contains a larger number of background references, some of which are indicated in the additional references. Data on the 1946 birth cohort were accessed with the permission of the Medical Research Council National Survey of Health and Development. The other British surveys cited are available at the UK Data Archive. The financial support of the Economic and Social Research Council to the Centre for Longitudinal Studies, ES/M001660/1, and for the project The Role of Education in Intergenerational Social Mobility, ES/I038187/1, is gratefully acknowledged.
Competing interests
The IZA World of Labor project is committed to the IZA Guiding Principles of Research Integrity. The author declares to have observed these principles.
© Heather Joshi
Examples of longitudinal cohort and panel studies
Cohort studies follow individuals from a common starting age through time.
Mature cohort studies follow a large national sample from birth or adolescence into adulthood, with data on mid-life:
MRC National Survey of Health and Development (NSHD), 1946 birth cohort, UK
National Child Development Study (NCDS), 1958 birth cohort, UK
Youth cohorts start at adolescence and follow individuals into adulthood:
Child cohorts start at pregnancy, birth, or a given point in childhood and follow individuals; most have not yet reached adulthood:
National Longitudinal Survey of Children and Youth (NLSCY), Canada
National Education Panel Study (NEPS), birth and kindergarten cohorts, Germany
Aging and retirement cohorts follow people around and beyond retirement age:
Household panel studies follow individuals of different ages in an initial sample of households.