Elevator pitch
Information from longitudinal surveys transforms snapshots of a given moment into something with a time dimension. It illuminates patterns of events within an individual’s life and records mobility and immobility between older and younger generations. It can track the different pathways of men and women and people of diverse socio-economic background through the life course. It can join up data on aspects of a person’s life, health, education, family, and employment and show how these domains affect one another. It is ideal for bridging the different silos of policies that affect people’s lives.
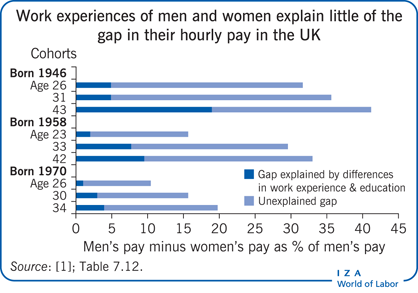
Key findings
Pros
Longitudinal surveys form a record of continuities and transitions of a life as they happen, information not reliably gained through recollection or cross-section surveys.
Such surveys can reveal how domains of life intertwine over time in the same person.
Information from an individual’s past helps unpack present observations and future expectations for that person.
Multiple applications and an ability to link to administrative data make longitudinal surveys cost-effective.
Analyses of such survey data may detect causation within correlation.
Cons
Longitudinal survey data are expensive to collect and challenging to analyze.
Data must be collected over a long timeframe to show relevant, long-term results.
Having usable longitudinal survey data requires that informants not drop out of the survey, which limits how much information they can be asked to provide.
Data confidentiality has to be safeguarded, putting hurdles across easy research access.
Caution is needed in inferring causality from observational data, where changes may not be independently generated.